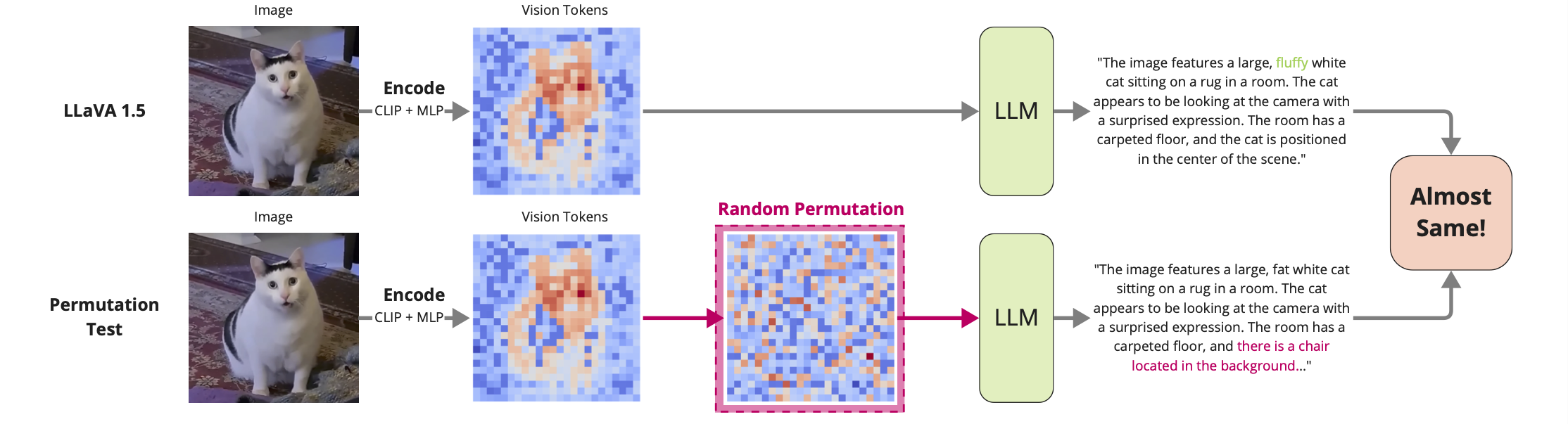
如果位置顺序对空间推理很重要,那么随机打乱视觉token的顺序应该会显著降低模型性能。但实验结果表明,这样的操作对模型的影响非常小,表明VLMs对token顺序不敏感,呈现出“词袋模型”倾向
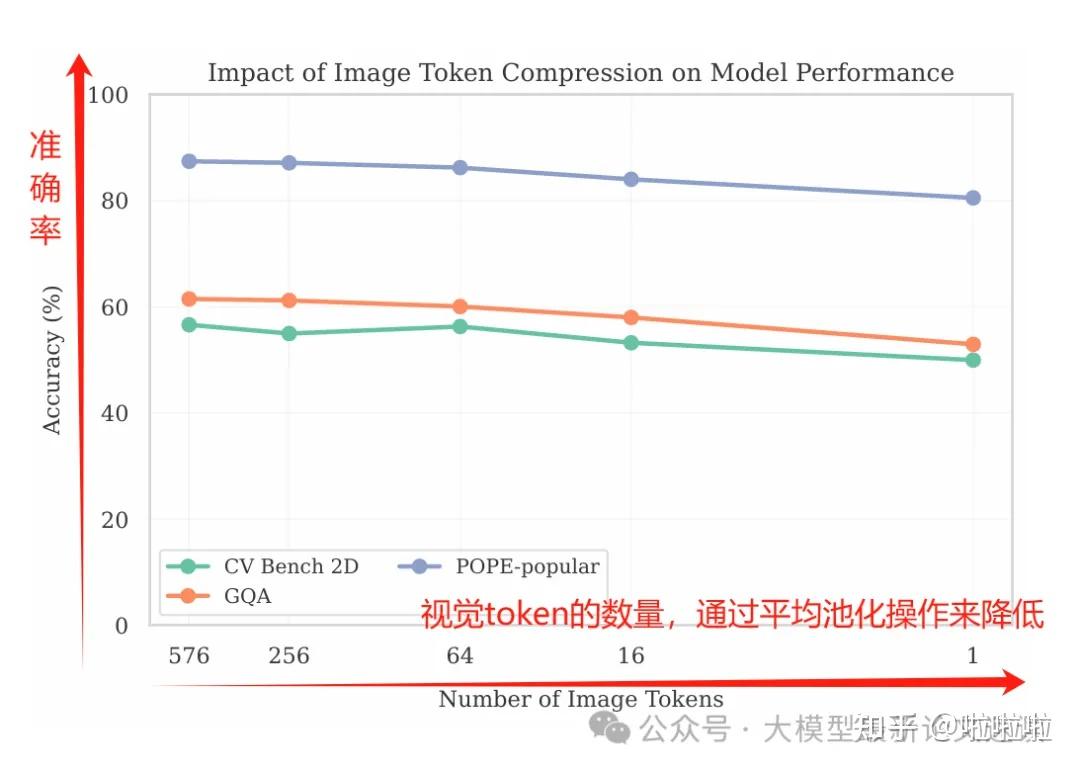
如果细粒度的空间信息很重要,那么通过池化大幅压缩token length维度的信息,会导致模型性能显著降低。但实验结果表明,即使将视觉token的个数从576减少到1,性能下降也非常有限,这表明在当前的VLMs中,空间信息对结果并没有多大贡献
我用qwen2.5 vl 做的 LaTeX OCR 可视化: